timeline
title Some (online Data) Context
2001: Google Earth
: satellite & aerial
2004: OpenStreetMap
: GIS
: crowd sourcing
2005: Google Map
: GIS
2006: Twitter
: Geolocated multimedia posts
2007: Google Street View
: Road Scenes
2013: Mapillary
: Road scenes
: crowd sourcing
Geotagging of Objects
Neural Networks based Solutions for Geotagging of Objects
2025-04-08
Introduction
Motivations:
- Infrastructure maintenance
- Infrastructure compliance (safety)
- Planning (e.g. EV public chargers deployment)
- Autonomous robotics
- Bio diversity monitoring
- etc.
Focus of this talk:
Static Objectgeotagging e.g. traffic signs, poles, trees (but \(\neq\) cars or pedestrians)

Early works

Detection of Changing Objects in Camera-in-Motion Video
Early works

Robust Object Recognition
Early works

Extension to object detection:
- several robust scores (based M-estimators) computed with a sliding window
- Bayesian probability interpretation of these robust scores.
- method robust to partial occlusion and cluttered background
Geotagging of Objects

Geotagging of Objects

Geotagging of Objects
Evaluation:
- Object Detection

Geotagging of Objects
Evaluation:
- Absolute GPS positions against ground truth
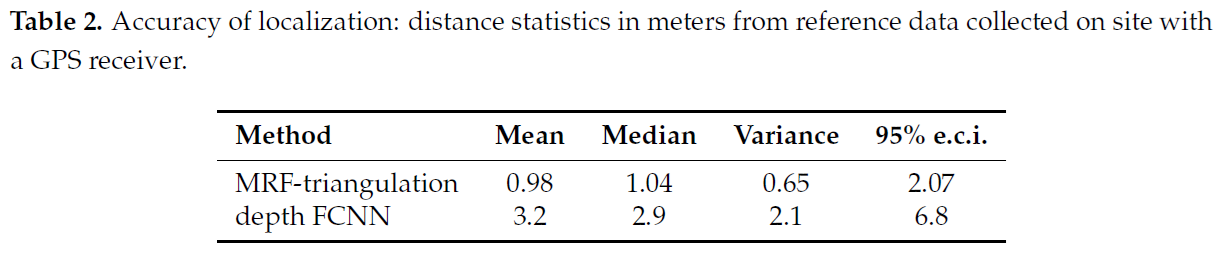
Geotagging of Objects
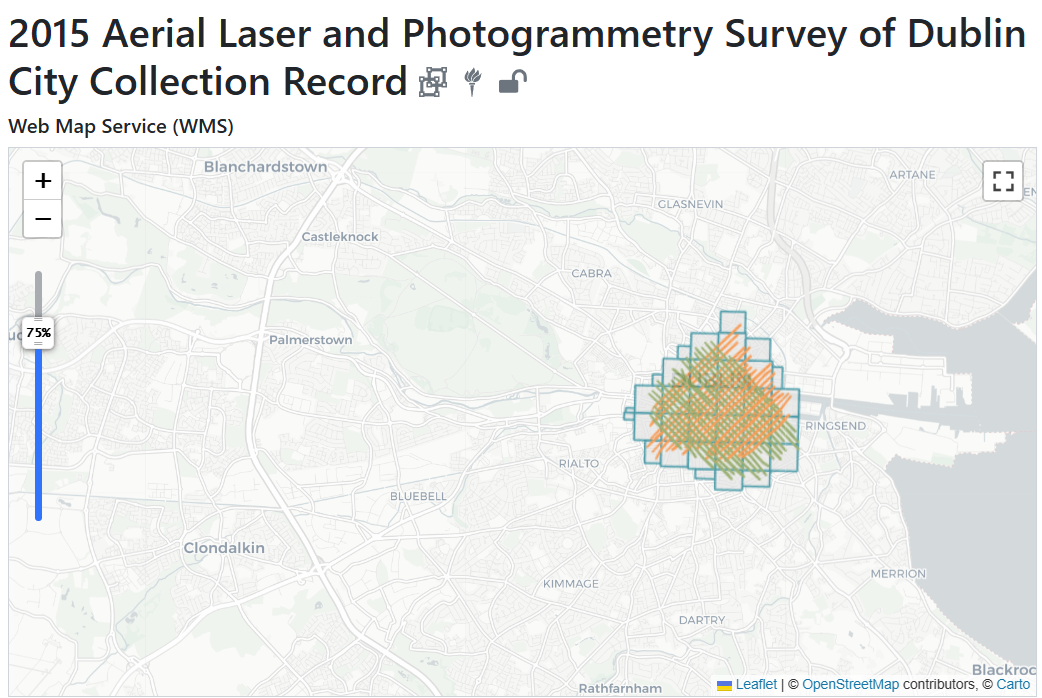
- Detection in Lidar point cloud performed by template matching using a pole-like object template (false alarm rate: high).
- The MRF energy is modified by adding a new term to take into account Lidar candidate locations near each of the MRF sites.
Geotagging of Objects
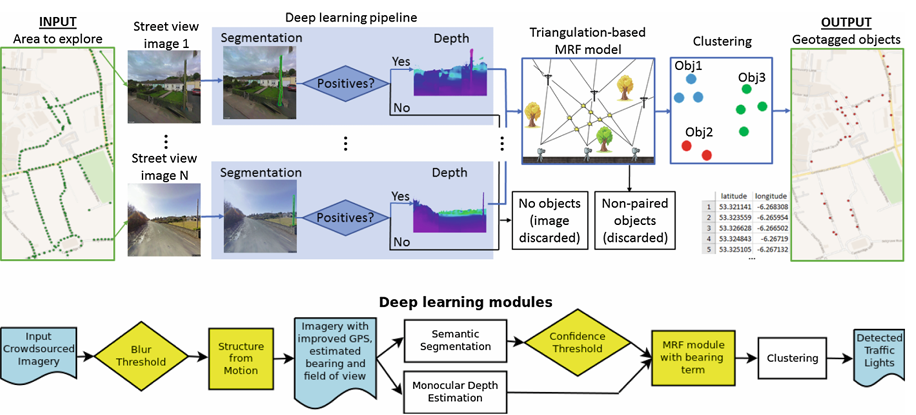
Evaluation was also performed with Mapillary crowdsourced images (bottom pipeline) instead of GSV (top pipeline for reference). Additional preprocessing is needed to inferred the missing image metadata in Mapilliary.
Geotagging of Objects

Research out of the lab!
Improving DNNs
In CNN, filter weights \(\lbrace \alpha_i\rbrace\) are learnt: \[ \text{filter for convolution}=\sum_i \alpha_i \ \mathbf{e}_i \\ \text{with} \ \lbrace \mathbf{e}_i\rbrace \equiv \text{natural basis} \]
We propose Harmonic CNN layer, where the natural basis is replaced by DCT basis,that:
- replace conventional convolutional layers to produce harmonic versions of existing CNN architectures,
- can be efficiently compressed by truncating high-frequency components,
- has been validated extensively for image classification, object detection and semantic segmentation applications.

Improving DNNs
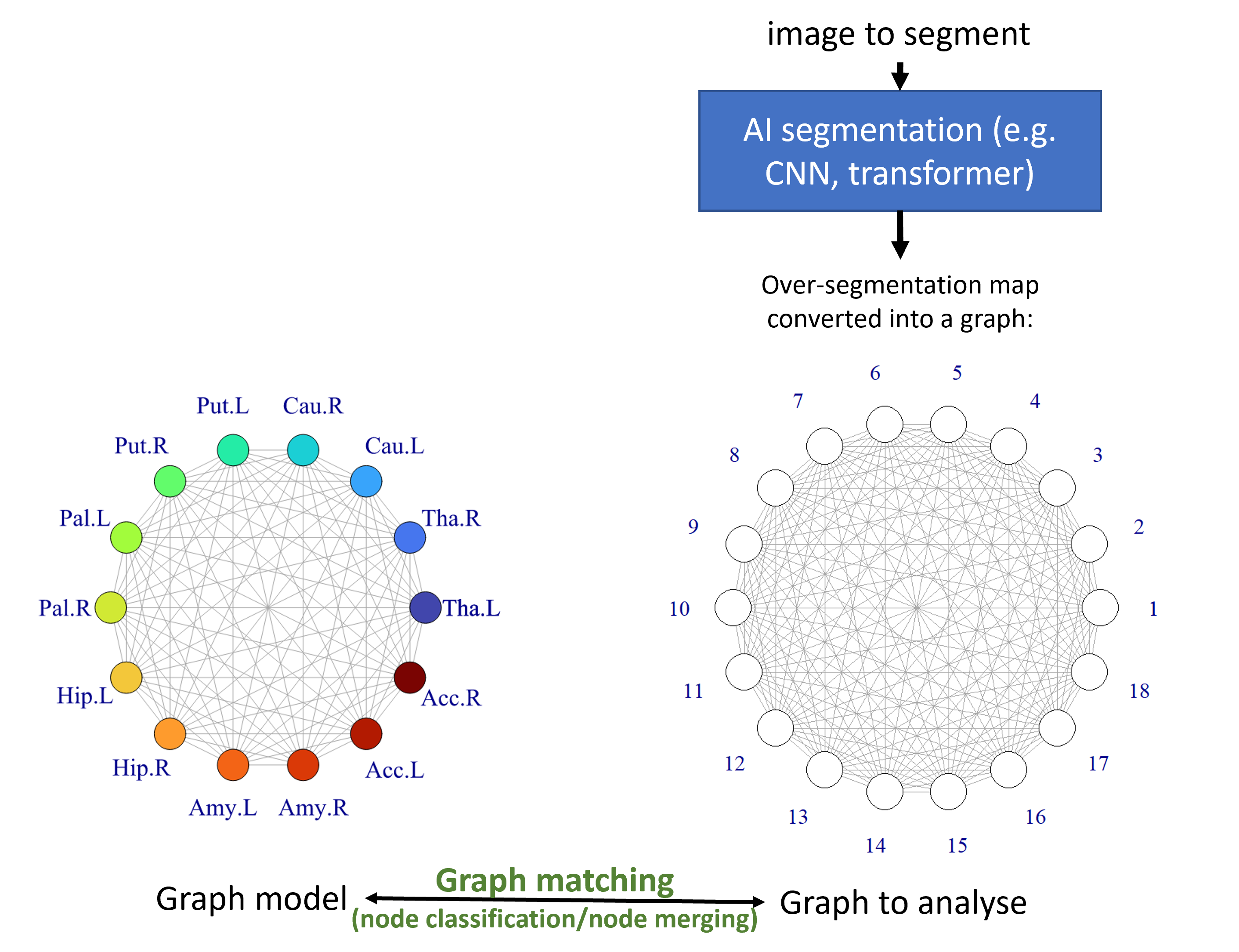
Graph matching as postprocessing of DNN segmentation results. Example for 3D segmentation of brain (IBSR dataset):
Thank you! Any Questions?

Many thanks to all my collaborators, past and present!
